Collaborative Coding for Simulation
-
@jack-waugh Sounds really difficult to do in a way where it is actually good strategy. For instance, how do you determine if a candidate is popular? Does it mean "likely to be elected under the current method?" Because that by its nature needs to be iteratively solved. (well, that's the only way I can think of to solve that). And then, how do you determine how good voters are at guessing how others will vote? Do they all have equal ability?
I also have trouble imagining how you decide what voters go in what faction, in anything approaching realism, unless you do something along the lines of what I did which is give each voter (and each candidate) a position in "ideological space", which I simplified into a 2-dimensional space. Note that in the latest version I also gave candidates a "universal appeal" property, so it wasn't only about proximity to the candidate in ideological space.
Finally, I don't know how to algorithmically do strategic voting under IRV or Condorcet. It seems like a voter needs to be able to guess with a great deal of precision how others will vote in order to effectively rank the candidates in anything other than your sincere preferences.
-
@rob I feel there is a certain amount of demerit in my spending more time jawboning about the simulation I have in mind than coding it. Nevertheless.
I am choosing to exclude from the scope of the simulation, any modeling of how or why the voters come to the evaluations they have of the candidates. I want to simply allow the researcher (the user) to specify those. The purpose of running the simulations is to see which combinations of strategies and voting systems do better in the sense of tipping the result the way the researcher is interested in (presumably, toward defeating the duopoly) with the least support in terms of count of voters on one side or the other with respect to whatever polarization interests the researcher. My idea is to allow the researcher to find this tipping point by titration, by adjusting a slider control back and forth and observing when the combinations of voting systems with strategies for them tip between electing the sort of candidate the researcher supports to the sort the researcher opposes. The slider position will affect the numbers of voters holding certain valuations of the candidates and nothing else. The valuations will drive the votes via the strategies. Every seriously proposed voting system has an obvious naïve strategy, and I will offer that in all cases.
For Condorcet and IRV, I don't know offhand any strategies to offer other than the naïve strategy, which is just to order the candidates according to preference. This is the strategy recommended by IRV advocates.
For Score (and STAR), the popularity of the preferred candidate is directly available in the simulation (as it would not be in real life) from the evaluations of the voters toward the candidates. A threshold could be chosen based on what the candidate scores would be in a forced "honest" Score election, based on reading the voters' minds rather than giving them freedom of choice. Maybe instead of a hard threshold, this should be a parameter to choose a logistic function through which to map the scores given to the middle candidates. I'm not sure whether that makes sense; it's just an idea. But generally, the idea is that if honest scoring would elect Nader, there is no need to settle for Gore or Bush, whichever we judge to be the lesser evil. But if Nader is polling at 1%, we might care about the Gore-Bush part of the election and would want to exaggerate support for the lesser evil.
So, my assumption is that all voters are perfectly good at guessing what the other voters want (not how they will vote), and as good as the author of the strategy routine at choosing an advantageous strategy. The reason for these assumptions is I am trying to pit the voting systems against each other, above all else. I want to find out, and show others, circumstances where one voting system "works" better than the other at overcoming the kinds of antidemocratic behaviors that FPtP exhibits. I believe that when a system has been in place for several elections, all factions will figure out how best to game it for their purposes, to the extent that is possible. My grounds for expecting this are general Darwinism plus the experience that every American knows that a naïve choice under FPtP is not always the most advantageous choice.
I haven't thought about any simulation that would address the choice that a potential candidate would make to run or not run, as a variable to be computed. But the choice not to run in FPtP is an example of how the public has come to understand strategy.
-
@rob said in Collaborative Coding for Simulation:
Finally, I don't know how to algorithmically do strategic voting under IRV or Condorcet. It seems like a voter needs to be able to guess with a great deal of precision how others will vote in order to effectively rank the candidates in anything other than your sincere preferences.
Usually in Condorcet, strategy involves trying to force a cycle. But you will then have the task of determining whether doing this is beneficial for you.
A general case for voting strategy might be to define some sort of distance between two elections based on the number of ballots changed (but perhaps assigning different weights to each ballot-vote combination, since some voters wouldn't want to participate in a strategy as it undermines what they want, also, if your supporters aren't easily persuaded to vote strategically, they might require higher weights; the weights would represent the difficulty of convincing a voter to cast a specific vote), and then a naive approach might be to find the election with a different outcome of nearest distance to the election that is expected, then for each voter to choose from the votes that they are willing to cast whichever vote either maximizes or minimizes the distance from the expected election given their chosen vote and the nearest different outcome, depending on whether they prefer it or not.
One challenge with this idea is that strategy is local, so the distance won't be valid everywhere. Another is that it doesn't take into account uncertainty in our estimates.
I think that this is a bit of a ways off from being something you could usefully code, but I think it could develop into a useful model.
Score Sorted Margins[100]; STAR[90]; Score[81]; Approval[59]; IRV[18]; FPTP[0]
-
@marylander said in Collaborative Coding for Simulation:
find the election with a different outcome of nearest distance to the election that is expected
Your choice of concepts invites me to reexamine which ones I'm emphasizing when thinking about strategy. A way to look at is to start by asking whether the freedom of movement available to our faction allows us cast better than a naïve vote in terms of the quality of the electoral outcome as measured by our values. The expected election might be the one that would result if we voted naïvely and our opponents bullet voted. If there's an algorithm that explores all around the envelope of what we can do in search of a better outcome, assuming the opponents continue to bullet vote, that could be interesting. If no better alternative election is found within that freedom of movement, we should vote naïvely in order to avoid perturbing the secondary indications of the election. If more than one better election is found, we should try to force the best one.
-
@marylander said in Collaborative Coding for Simulation:
Usually in Condorcet, strategy involves trying to force a cycle. But you will then have the task of determining whether doing this is beneficial for you.
Yeah my feeling -- and it is more of a feeling than anything I've been able to mathematically reason -- is that for a normal voter to try to do this is going to be beyond their capabilities. They might try, but they are probably equally likely to do something has a negative effect as to have a positive effect. And if it does have a positive effect, it will be an extremely subtle one.
This is nothing like how under other systems -- such as FPTP, Approval, and Score -- simply knowing who the two front runners are dramatically helps you to vote effectively. Even being able to narrow it down, say from a field of 8 to a field of 4, makes a big difference.
-
@rob said in Collaborative Coding for Simulation:
Yeah my feeling -- and it is more of a feeling than anything I've been able to mathematically reason -- is that for a normal voter to try to do this is going to be beyond their capabilities. They might try, but they are probably equally likely to do something has a negative effect as to have a positive effect. And if it does have a positive effect, it will be an extremely subtle one.
I think there are simple cases where it might be possible for voters to use Condorcet strategy, if only because a campaign might be able to figure out some burial scenario and try to communicate to their voters "do this, just trust me." I have center-squeeze cases in mind in particular: often when the plurality winner has 1 pairwise win and 1 pairwise defeat to the (sincere) Condorcet winner, they'll win if their voters bury the sincere Condorcet winner. If the plurality winner's pairwise victory is large enough, the risk of this strategy is low. But the campaign itself would have to push this, since voters are not very good at figuring out strategy when left to their own devices.
-
@jack-waugh on the original question regarding languages, I don't really know FORTH (or its variations) and I have a strong attraction to LISP. But for the simple and practical reasons that simulations have to be run on some system, having JavaScript client code is really the only way to go if you want more than a handful of users running simultaneous simulations.
-
If you are looking for voting strategies and you aren't already familiar with it, you might want to look at Warren D. Smith's 2000 Range Voting paper. In it he proposes Range Voting (now more commonly referred to as Score) and compares it to about 30 other voting methods (really 14 other methods with naïve and strategic variations), The last I checked the paper can be found at Range Voting. The (c) code is also available at votetest2.c.
According to the (many) voting papers I've read over the past several years, there is a major decision that needs to be made when representing the electorate. In my opinion, the worst option is to use tournaments, which essentially ignore voters and even elections, and are about choosing a winner among a fixed set of alternatives based on a graph in which an arrow points from node A to node B if A would defeat B in a one-on-one simple majority election. The graph is just a given, and the challenge is to figure out a way to pick the winner. These papers have tended to focus on the computational difficulty of making this choice when the graph is large. The second way of representing the electorate is preference profiles, which is just a ranking of the fixed set of alternatives combined with a mulitplicity for each raking indicating how many voters would order the alternative that way. My problem with this method is that it doesn't provide any data for approval voting or score voting, or indeed any cardinal voting method.
My preferred method (which generally requires computer simulation for any realistically sized electorate) is to represent voters as points in an issue space (usually 2D or higher), and use a distance function between the voters and the alternatives (also points in the issue space) to generate ordinal or cardinal ballots.
One of the projects I'm considering is to start with something like Nicky Case's To Build A Better Ballot, and use interactive JavaScript to illustrate many of the problems with various voting systems. This is also similar to what @rob did in the underlying electorate model in his voting strategy simulation. (I do have an ulterior motive here. If the simulations start with the voters and distance functions to the alternatives, it becomes a lot easier to show exactly how an iterative voting system like SAVE would work, and how it would be significantly better than any non-iterative system. That argument is a lot easier with pictures.)
-
@tec said in Collaborative Coding for Simulation:
My preferred method (which generally requires computer simulation for any realistically sized electorate) is to represent voters as points in an issue space (usually 2D or higher), and use a distance function between the voters and the alternatives (also points in the issue space) to generate ordinal or cardinal ballots.
......
This is also similar to what @rob did in the underlying electorate model in his voting strategy simulationYes that is exactly what I do. The thing I do that isn't realistic at all, though, is that I simply spread the voters around with a random distribution, rather than having any clustering at all. That said, most of the clustering in US politics today is, in my opinion, caused by the voting system itself. Duverger's law and such. So I erred in the opposite direction, and assumed that it was spread evenly among the electorate. The orange/gray/blue dots below represent voters in "issue space" (or "ideological space"). The crosshair simply indicates the median value of X and Y.
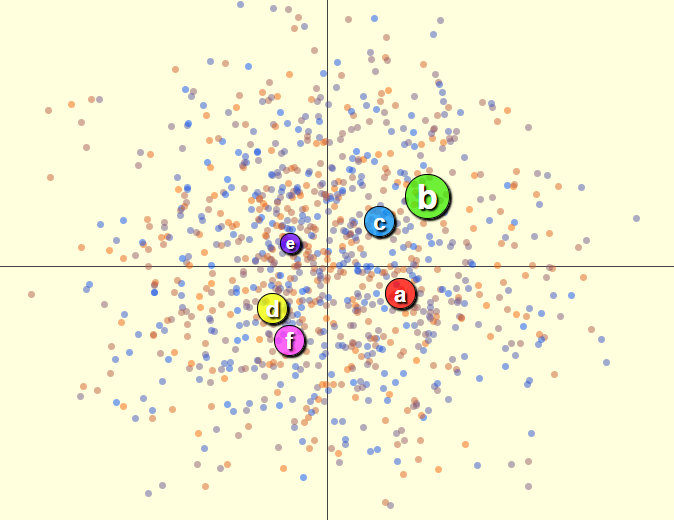
I use 2 dimensions rather than more because it is easier to show on screen, as well as just being the right level of complexity to illustrate concepts to people (which I prioritized a bit higher than making it fully realistic). Both candidates and voters have an X and a Y value. When talking about it, I usually consider X to mean "left vs. right", both in a geometrical sense but also political. (so I can talk about "voters on the left" indicating liberals/democrats, at least in the US politics sense)
In addition to X and Y values, voters have another property which is "how strategic they are." This is shown in the color: orange is fully strategic, blue is fully sincere. I use this in a simplified, but not totally unrealistic way: those that are the most strategic vote as if they know for sure who the two front runners are, those who are most sincere vote as if they consider every single candidate equally likely to be elected. Those in the middle will vote as if some in-between number of candidates (say, 4) will be front-runners.
Meanwhile, candidates (large colored dots with a letter on them) have a property beyond their X Y position in issue space, and that is what I call "universal appeal." This can include things like their appearance, their speaking skills and debating skills, their intelligence, and so on. Basically, those things that are deemed good regardless of what a voter's position on issues are. So candidate B above has higher universal appeal than others, while candidate E has lower universal appeal. This is shown by size. (note that the video I shared earlier did not have this as I hadn't implemented it yet)
Notice that I have also added one more thing to the simulation, which is the "Raw" scoring in the output. (at right)
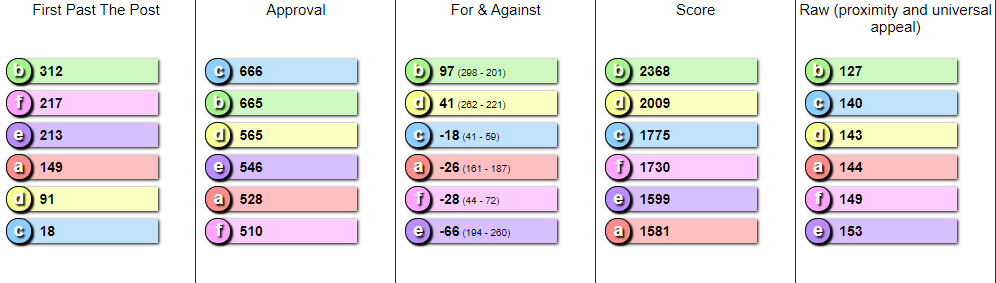
This is not calculated based on any vote, but just by determining the average "voter satisfaction" at their being elected. I consider this to be an indication of what is the best winner actually is. This only works because the app has the ability to essentially read the voter's minds --- for the actual voting methods, the app can only look at their ballots.It is expected that the raw scoring "method" will tend to give the candidate nearest the median (i.e. the crosshair) the highest score. More or less. And this assumes that all have the same universal appeal.
I haven't yet tried to do Condorcet methods, STAR or IRV, since strategy is so much more complicated for them.
(the app in its current form -- i.e. unfinished -- is at https://pianop.ly/voteSim/voteSim.html . To use it, first click "make voters", then click around to place candidates, then click "vote". You can delete candidates by clicking on them, you can adjust their universal appeal by mousing over them and using up and down arrow keys, or by using the "default UA" slider prior to placing them)
-
Codesandbox
If you have a github repo, you can automatically deploy to CodeSandbox.io to give a sandbox for your creations.
Here's an example I'm working on: https://codesandbox.io/s/github/paretoman/votekit
Embeds
Also, we might be able to embed examples here: https://codesandbox.io/docs/embedding
But that is something that would have to be specifically set up somehow on NodeBB, and I don't really know about that. For now, a link is good.
-
@rob, does this code represent voter affinities toward candidates?
Approval-ordered Llull (letter grades) [10], Score // Llull [9], Score, STAR, Approval, other rated Condorcet [8]; equal-ranked Condorcet [4]; strictly-ranked Condorcet [3]; everything else [0].
-
@jack-waugh said in Collaborative Coding for Simulation:
@rob, does this code represent voter affinities toward candidates?
Are you speaking of Paretoman's code? I don't know what it represents, I ran it quickly but in the absence of a good explanation I don't know what it is supposed to be showing.
Personally I'd recommend a video demo if he cares to do one. OBS and YouTube are your friends.
-
@paretoman said in Collaborative Coding for Simulation:
Maybe _codesandbox_ is part of a good solution, but, to date, I haven't taken time to look into it, because I am already using [0] a hosting solution that provides full flexibility.
-
If anybody would feel inclined to make their tabulation API 'black boxed' so you can just hand me a .csv file and I will hand you a list of winners, I would be happy to implement a great number of voting methods, including some of the most complicated like Stable Voting or Meek-STV.
I do want to contribute, but I'm just much more comfortable iterating on local scripts in Julia or Python than I am with JS. Does JS have the ability to invoke command line scripts?
-
@andy-dienes JS can be run on the command line via node.js, which is quick to download and install and generally "just works". Of course it also allows you to run web servers and the like, but you can also just say "node myprogram.js" to run things from the command line on mac, windows and any flavor of linux.
I prefer things like Codepen, though, because it is so easily sharable. You can just point people to the Codepen url, and they can paste whatever data in they want. They can also fork it if they want to edit the code. I did a bunch of work to parse ballot formats that are easy to use in forums. (comma separated aren't terrible, but that seems a bit more optimized for the machine rather than for human eyes, and I prefer optimizing for humans)
See https://codepen.io/karmatics/pen/ExKZVjM for example. You can paste in data or use the default. (just click "tabulate" in the bottom right)
But yeah if you prefer work at the command line, but do it in javascript, I'd be glad to convert them to Codepens (or set up a simple template so you can do it yourself), so you can just refer people to a url rather than having them send you csv files, which doesn't lend itself to experimentation and such.
-
@rob Oops, let me clarify. Does JS have the ability to easily call other scripts from command line? Something like Python's subprocess.call()
-
@andy-dienes I went back and thought about what you asked, I think the answer is "yes":
https://nodejs.org/api/child_process.html
However I first thought you were asking how to include one JS file in another, or spawn a thread, or whatever... I'll just leave what I wrote about all that.....
Here I'm using modules.exports and require in the normal way to include one js file in another (and call a function in the included module from the original file):
main.js
console.log("hello there"); var otherModule = require("./included.js"); otherModule.sayHi();included.js
module.exports = { sayHi: () => { console.log("hi!"); } };then run it:
> node main
hello there
hi!I'm not sure what you're trying to do.... spawn a thread? Javascript is single-threaded typically but uses callbacks (and the more modern async and promise stuff) when you want to start something that runs separately. I mostly do that for animations or various UI stuff, but that tends to be overkill for just, say, running a calculation that runs in a few milliseconds.
There is also WebWorkers which are essentially background threads. (yes they work in non-browser environments like node.js) I've never had the need for them.
BTW, if you are interested in checking out Codepen, I made a super simple starter app that allows you to do really basic stuff that might be relevant to us (such as process text input and produce text output), with a easy to use UI. Anyone should be able to follow it.
-
@rob said in Collaborative Coding for Simulation:
I'm not sure what you're trying to do.... spawn a thread?
I'm wondering if there is some way to run
js.run_shell_command("julia my_awesome_and_hard_to_implement_voting_method.jl --election=ballot_data.csv --seats=3 --output=winners.csv")Some of these algorithms are quite pleasant to implement given tools & libraries present in Julia / Python, but I wouldn't even know where to look for the same in JS. Maybe just for mental context, pretend I'm talking about implementing Schulze-STV which involves solving a linear optimization program for every single pair of possible sets of winners.
-
@andy-dienes
Probably exec() is what you want, although spawn() is a bit more powerful I think for long running programs.Here's exec. Most of the bulk below is just showing how to handle all the stderr etc.
const { exec } = require('child_process'); const newProcess = exec('julia my_awesome_and_hard_to_implement_voting_method.jl --election=ballot_data.csv --seats=3 --output=winners.csv', function (error, stdout, stderr) { if (error) { console.log(error.stack); console.log('error code: ' + error.code); console.log('signal: ' + error.signal); } console.log('stdout: ' + stdout); console.log('stderr: ' + stderr); }); newProcess.on('exit', function (code) { console.log('exited with exit code ' + code); });I don't know what to suggest as far as Schulze-STV, that method makes my brain hurt. But I'd hope you can implement it with just some for loops or basic recursion.... right?
-
@rob said in Collaborative Coding for Simulation:
But I'd hope you can implement it with just some for loops or basic recursion.... right?
Alas, no. It requires solving a linear program (aka an optimization program that looks like this) for every single pair of possible committees, of which there are exponentially many... I have implemented the algorithm using JuMP for which there are a number of convex solvers (e.g. COSMO, Clarabel, or the more canonical CLP), and in Python there is stuff like Pyomo, cvxopt, or even just scipy, but the corresponding JS libraries seem less pleasant to use.
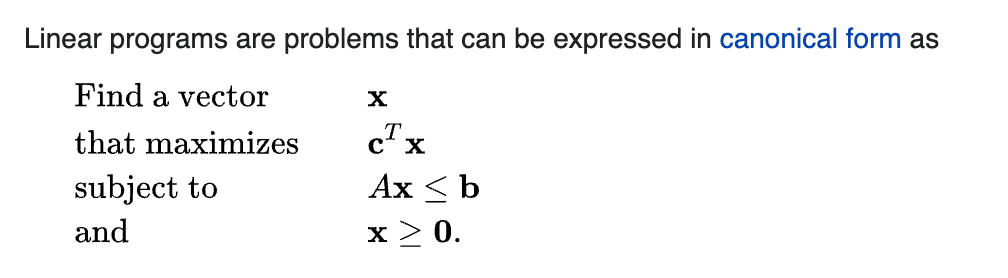
There are other methods too for which some serious complexity is needed like the above. More examples are the strategy-proof randomized Condorcet methods (1) and (2). Also, there are methods which technically can be implemented with simple algorithms, but really benefit from just having the language be natively fast, e.g. Stable Voting or PAV; similarly if some kind of Monte Carlo simulations are desired, one can run a whole lot more of these in a whole lot less time using Julia / Numpy than I imagine one could ever do in JS.
I am not criticizing the choice to use JS and there seems to be a good context to use it here---I'm just trying to give reasons why it might be useful to 'black box' the actual winner selection into separately-executable scripts.